
¿Quién no ha sufrido, en mayor o menor medida, perdidas de conectividad a los servicios IT?
Los que nos dedicamos al mundo de las redes bromeamos con que la culpa de cualquier problema siempre apunta en primer lugar a la red. El control directo de los administradores es cada vez más complicado debido al uso de líneas de internet, cargas en el cloud, servicios externalizados… por lo que es importante saber cuales están siendo los problemas más repetitivos que las redes están sufriendo: BGP, DNS, ISP, CSP, CDN… y como darles solución.
PROBLEMAS RECURRENTES

- Problemas por Conectividad
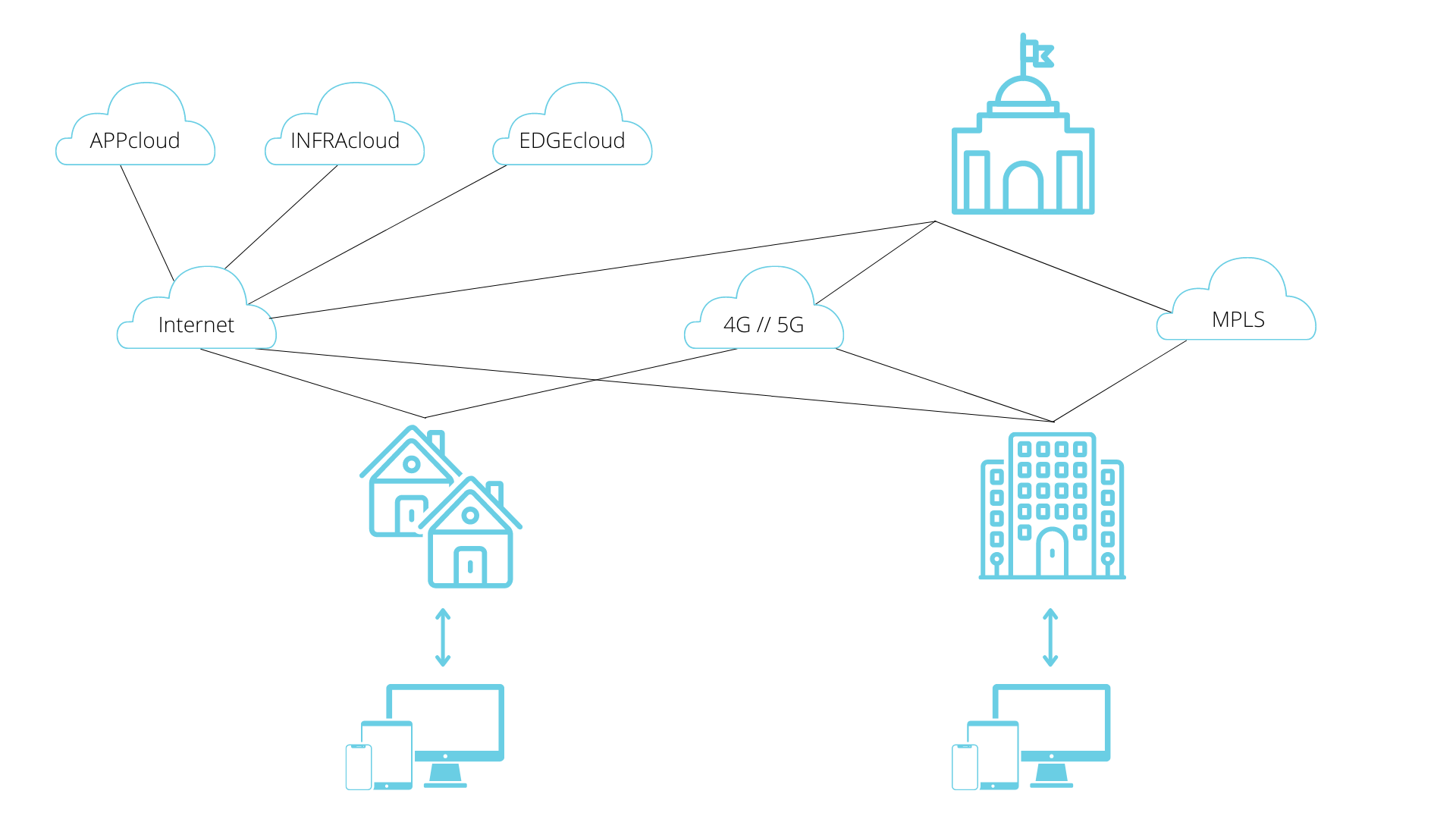
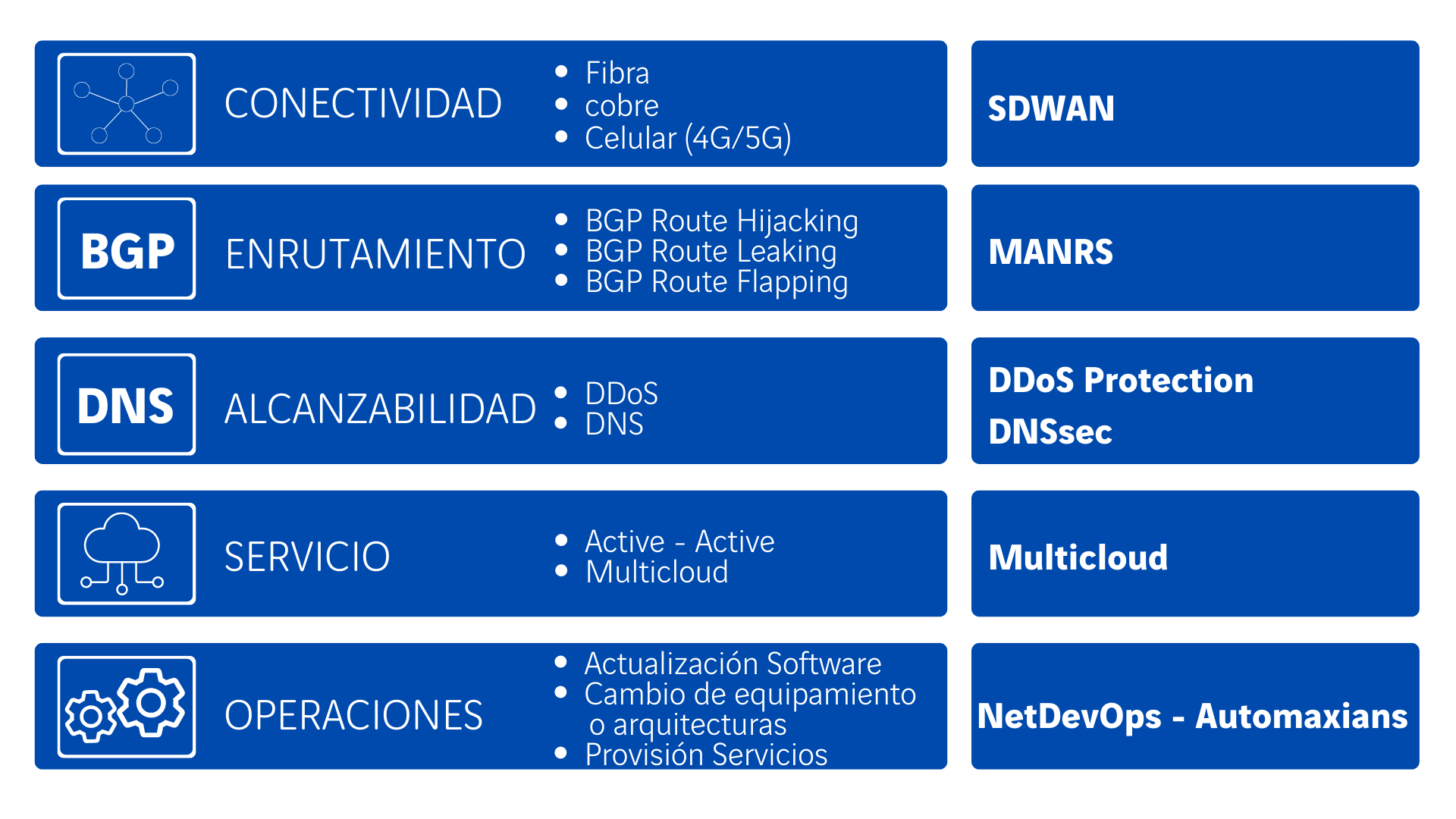
En esta categoría contemplamos las caídas del servicio por indisponibilidad de líneas de comunicaciones. Hablamos en este caso de proveedores de líneas dedicadas (NSP: Network Service Providers), pero también de proveedores de líneas de Internet (ISP: Internet Service Providers), tanto en nuestras sedes remotas como en nuestros centros de datos. Estas caídas pueden ser bien por el fallo de los dispositivos activos de comunicaciones (routers, switches, olt, ont, dwdm…) o por las rotura de los medios de transmisión empleados (fibra, cobre). Desgraciadamente, es más habitual de lo deseado, escuchar noticias de grandes caídas por la rotura de una manguera de fibras por culpa de una excavadora.
Para mitigar esta problemática lo más recomendado es tener redundancia de líneas, donde la redundancia contemple el acceso físico por acometidas diferenciadas, con proveedores distintos y con tecnologías de acceso diferentes (fibra, cable y celular). Para hacer un uso óptimo de esas líneas se emplean tecnologías como SDWAN, donde en primer lugar se realiza una abstracción del transporte implementado (Transport Independency) y donde se emplean funcionalidades como «cloud on-ramp» o «software-defined cloud interconnect» para monitorizar el destino final y poder así elegir el mejor camino disponible a distintas regiones y pop de los CSP (Cloud Service Provider).
- Problemas de Enrutamiento
En un mundo digital, en el que las amenazas de seguridad son cada vez mayores, ni siquiera el protocolo de routing más estable que tenemos (BGP: Border router Protocol), podría librarse.
BGP se definió a finales de los años ’80, y ha ido evolucionando en estos últimos 40 años. Es el protocolo estándar para el intercambio de rutas (prefijos) entre los sistemas autónomos (AS) que identifican a las compañías. Sin entrar en detalles de su funcionamiento (iBGP, eBGP, RouterReflectos, Communities…) consideremos que puede suceder, si de manera intencionada se comienzan a realizar anuncios de prefijos desde equipos inválidos. Podrían producirse pérdidas de servicio descartando todo ese tráfico «secuestrado», o analizar esa información cautivada de manera ilegal. Periódicamente vemos ataques de este tipo en el que el tráfico de un ISP o un CSP es robado desde ubicaciones internacionales ajenas a la principal.
Hay distindos mecanismos para lograr estos problemas de enrutamiento (BGO Route Hijacking, BGP Route Leaking, BGP Route Flapping…) y distintas maneras de protegernos de los mismos, cada vez más avanzadas y seguras como pueden ser MANRS (Mutually Agreed Norms for Routing Security) donde mediante técnicas de filtrado y validación basado en certificados aseguramos la integridad de estos anuncios.

- Problemas de Alcanzabilidad
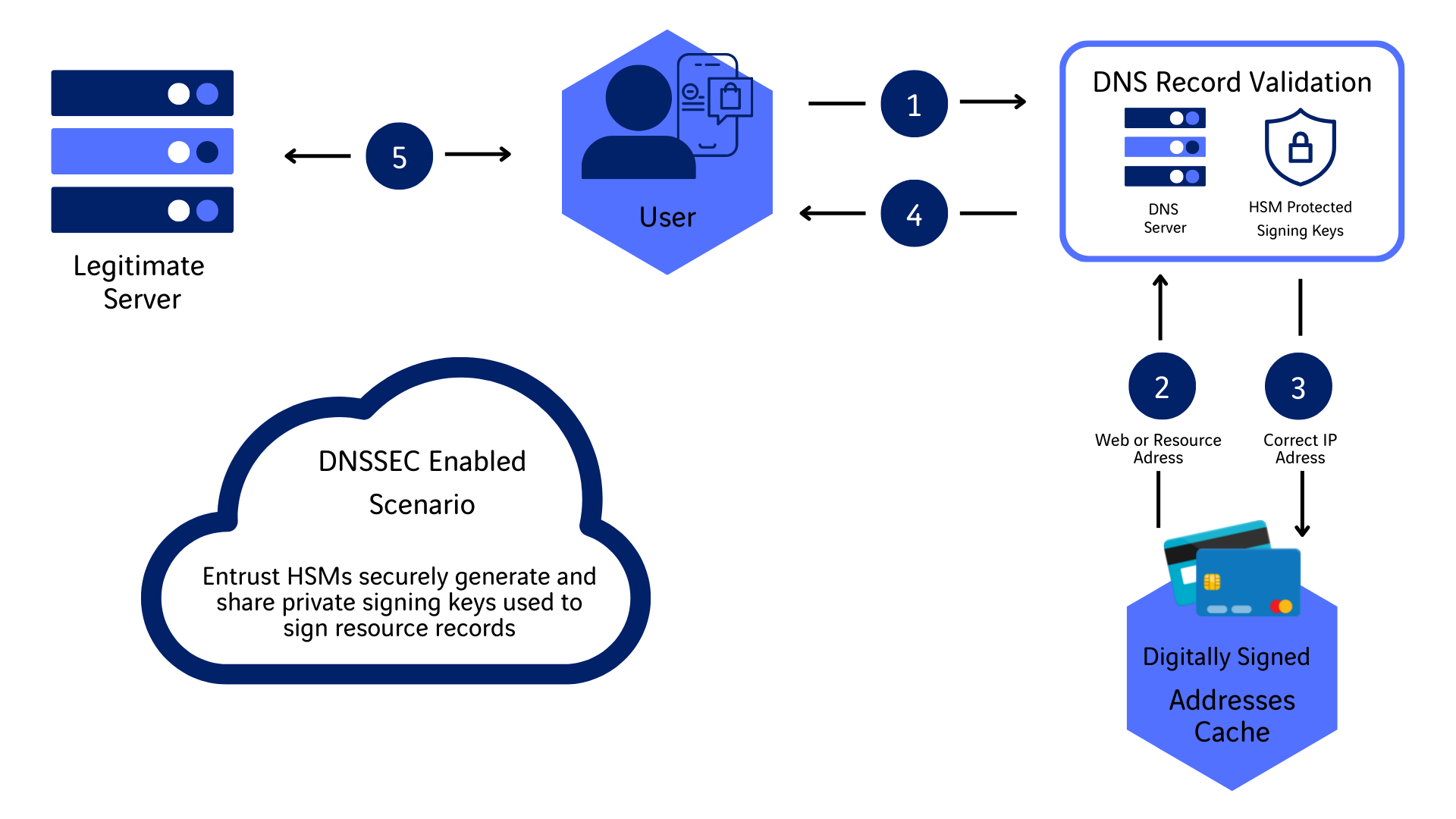
En esta categoría vemos que la amenaza más importante que debemos contemplar son los ciberataques. Por ejemplo, los ataques distribuidos de denegación de servicio (DDoS: Distribited Denial os Service) provocan ataques a servicios de internet mediante la generación de una ingente cantidad de solicitudes que no son capaces de procesarse. Esto hace que esos servicios de internet dejen de prestar servicio, pero también provocan congestiones en las redes que transportan esas peticiones que se traducen en pérdidas de paquetes e incremento de latencias. Hay otras técnicas de ciberdelincuencia que afectan a las redes como puede ser el envenenamiento de DNS con técnicas como DNS Hijacking o DNS redirection, DNS spooping o Cache Poisoning, DNS tunneling…
Existen diversas tecnologías para defenderse de estos riesgos, desde los servicios de limpieza de tráfico, pasando por la utilización de las extensiones de seguridad de DNS (DNS see) o empleo de soluciones distribuidas (DNSblockchain) y acabando por técnicas de control de acceso y empleo de modelos zero-trust.
- Problemas por caída de servicio.
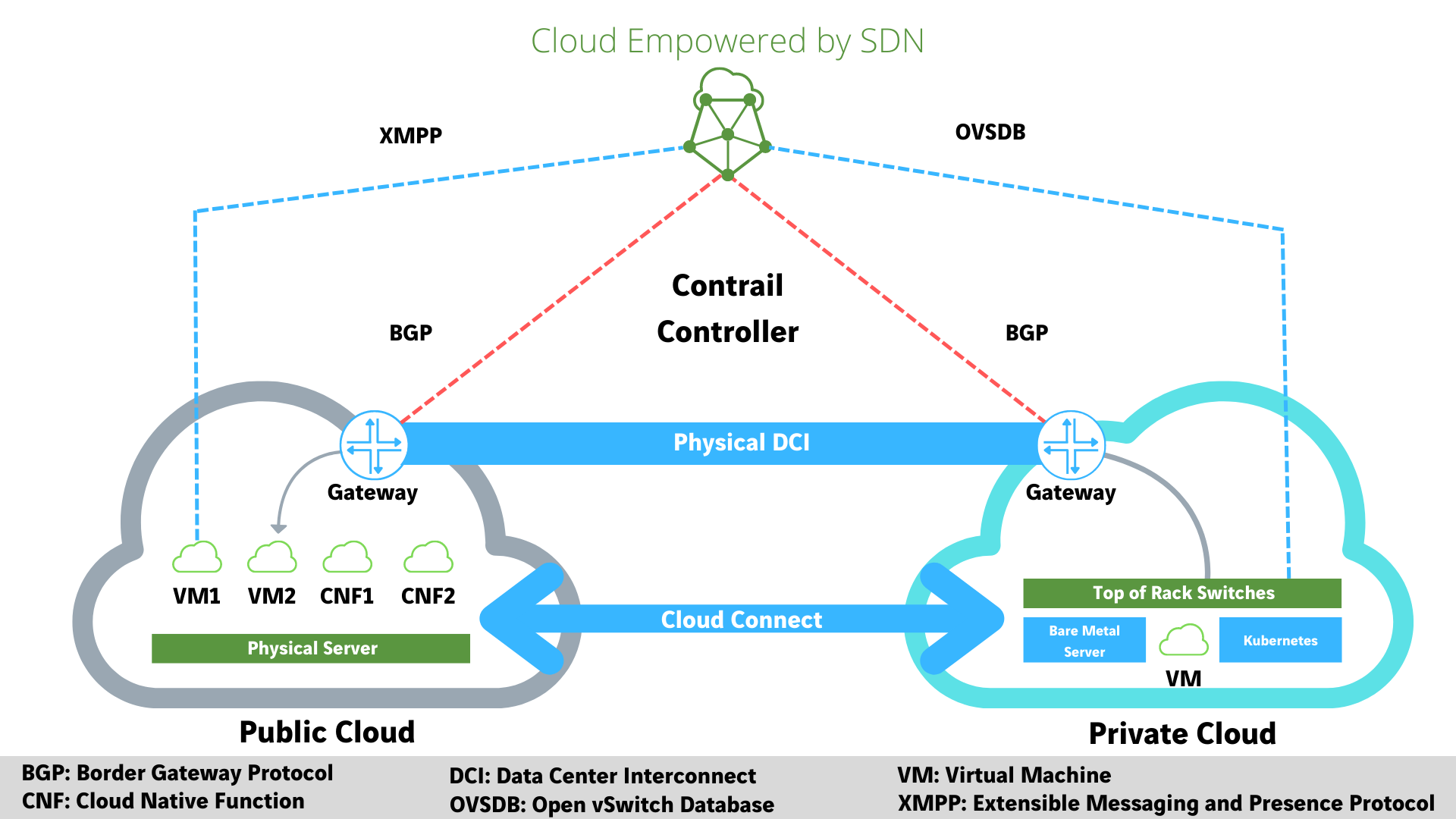
Durante muchos años hemos estado acostumbrados a contar con uno o dos centros de datos en la mayoría de las compañías. En muchas ocasiones ambos activos, pero en muchas otras siguen estando en modo activo-pasivo (Disaster Recovery). En los grandes proveedores sí que el número siempre ha sido más alto. Y en los grandes titanes de internet (GAFA: Google , Amazon, Facebook, Alibaba…) hemos visto como han creado regiones de disponibilidad, con varios sites o POPsen cada región. Todo para tratar de, por un lado, tener el servicio lo más cercano al usuario final; y por otro lado tener la mayor disponibilidad posible, incrementando el número de nueves (99,99%). Aún así, es inevitable, por unos motivos o por otros, contar con pérdidas por indisponibilidad del servicio.
Soluciones multicloud, tanto a nivel de comunicaciones como a nivel de computo y servicio están siendo las aproximaciones más empleadas por las compañías, aparecen aquí términos como cloud on-ramp, software-defined cloud interconnect, service mesh, orquestación multicloud…
- Problemas por Error de Operaciones
Las redes son cada vez más complejas, necesitan cada vez, cambios más rápidos y se han vuelto en infraestructuras cada vez más críticas. Una vez nos hemos protegido de las anteriores amenazas (líneas y conectividad, enrutamiento y BGP, ciberataques con DDoS y envenenamiento de DNS, usamos distintas clouds en distintas regiones…) tenemos que evitar que las actuaciones que realizamos en la red (actualización de versiones, cambios de equipamiento, modificaciones de arquitecturas, provisión de nuevas configuraciones…) provoquen degradación en el servicio.
Estas operaciones han sido tradicionalmente manuales, en ventanas de actuación controladas y de manera muy justificada, lo cual siempre nos ha llevado a estar en un círculo vicioso en el que el cambio lo vemos como una amenaza adicional. Es necesario un cambio de mentalidad. Cada vez vemos en más compañías como esa inercia empieza a cambiar de rumbo y nos acercamos a modelos de trabajo DevOps (NetDevOps, SecDevOps…) donde el cambio es una oportunidad en lugar de una amenaza.
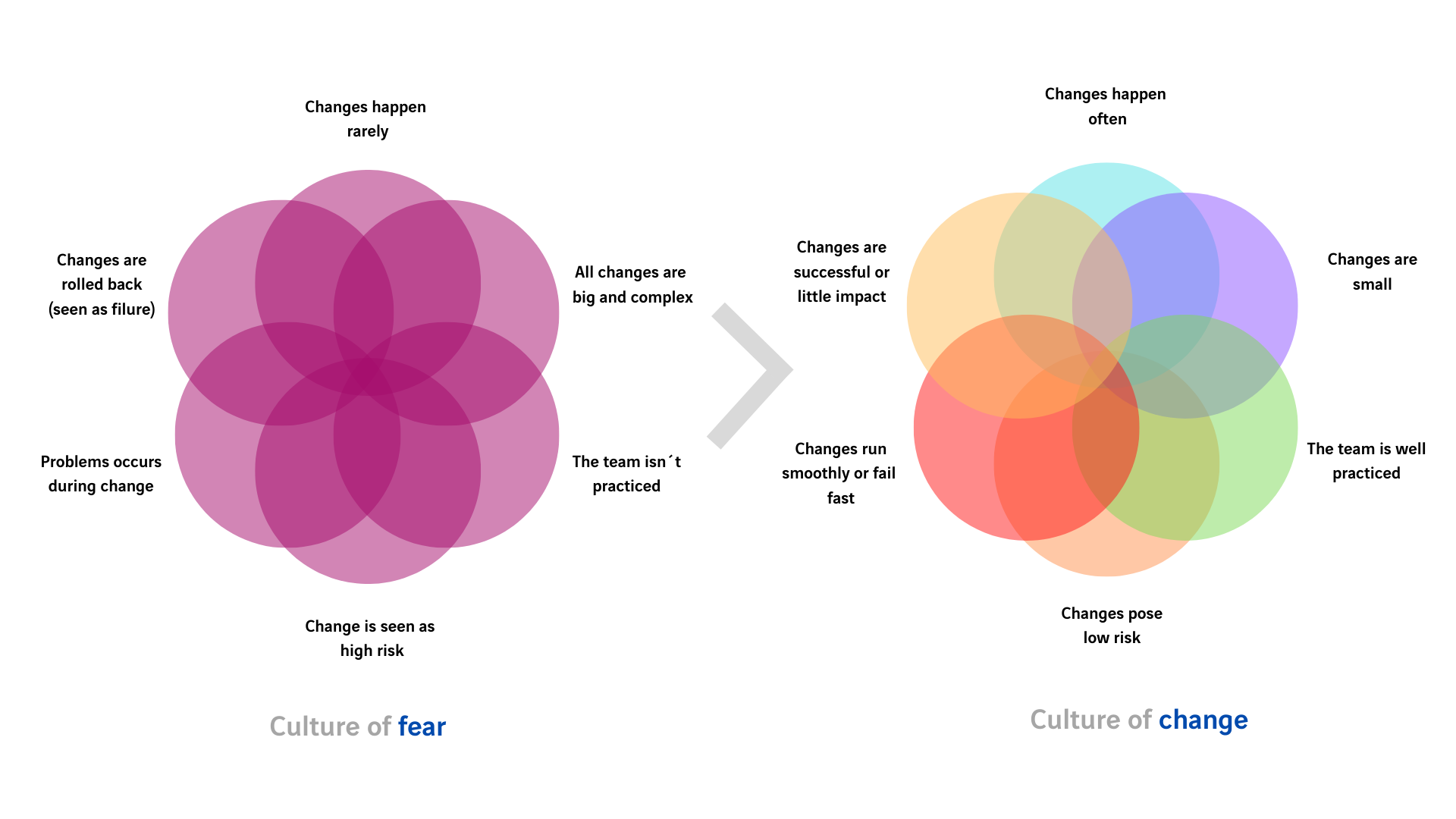
En ese modelo DevOps la autorización de las tareas, bien mediante herramientas comerciales, mediante la construcción de herramientas as-hoc, el empleo de herramientas open-source o el uso combinado de las tres, hace que los errores de operación sean residuales. Adicionalmente los equipos de trabajo pueden dedicar su tiempo en tareas de mucho más valor.
CONCLUSIONES
Como hemos visto tenemos ciertos riesgos que causan caídas parciales o totales de servicio que debemos evitar o al menos minimizar utilizando todo el arsenal de herramientas tecnológicas con las que contamos.
Adicionalmente debemos ir pensando en el empleo de tecnologías que nos acerquen a un Self-Driving Networks para que ante eventos la propia red se autoconfigure y autoproteja. Para ello es importante el uso de redes basadas en intención (IBN: Intent-Based Networking) y redes definidas por software (SDN: Software-Defined Network) y contar con herramientas de monitorización de la experiencia de usuario (CX: Customer eXperience).
En esta última parte cada vez es más necesario el despliegue de agentes, sondas o robots que midan y monitoricen la experiencia digital (DEM: Digital Experience Monitoring) y que nos den visibilidad de la red (NPM: Network Perfomance Monitoring), Tanto de la que administramos y está bajo nuestro control como la que se encuentra fuera (conexiones internet, caminos, saltos y convergencia BGP, rendimiento DNS y CDN, retardos con regiones cloud o SASE…) Para tener evidencias claras. Por último, hay que destacar la «socialización» de este tipo de información, cada vez hay más evidencias reportadas en redes sociales o con aplicaciones que desde la comunidad aportan visibilidad de forma altruista.
Necesitamos evaluar e implementar todas las medidas necesarias para protegernos y dar continuidad al negocio, a la vez que poder tener evidencias para de una manera rápida acotar posibles degradaciones de servicio, identificar el motivo causante y ejecutar las medidas correctoras necesarias. También para no recibir llamadas en las que nos digan: «Se me ha caído internet, ¡mirad a ver qué pasa en la red!»